Read on Medium here
Photo by Aron Visuals on Unsplash
SQL has become a common skill requirement across industries and job profiles. Companies demand that their data analysts, data scientists and product managers are at least be familiar with SQL. This is because SQL remains the language of data. So, in order to be data-driven, people need to know how to access and analyze data.
When I looked for resources to learn SQL for my role as an Analyst and prepare for interviews, all the websites had a very standard set of ‘Employee — Salary’ tables with very basic queries. While I did understand the basics of SQL well from such examples, it missed on which concepts were most important in a practical setting where we usually work with bigger queries. So I decided to summarize the key tips which I wish I had emphasized on when beginning my journey.
Know your basic query structure
This is the most basic and important tip. No matter how complex the problem, you should have the basic structure in mind and breakdown every part of your query into this structure. Even when I work with multiple tables and joins it always help to keep the basic structure in mind.
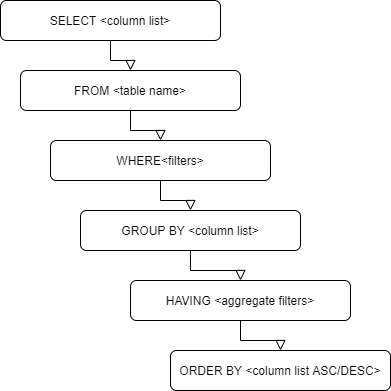
Basic SQL Query Structure
Know your Ranks and Partitions
In my years as an analyst and giving several interviews RANK/SUM OVER (PARTITION BY ____ ORDER BY) is one of the most used functions. This is used to rank rows based on particular value and partitioned by other attribute or find rolling value of aggregate functions.
It is important to always use row_number over rank/dense_rank when you need unique ranks for all your rows. (The difference between 3 types on rank functions is a common interview question. Here is a good summary for reference.)
These functions can help us in multiple problems for example :
Finding the latest entry in a particular filter —
SELECT city, booking AS latest_booking
FROM
(
SELECT city, booking, rank() over (partition by city ORDER BY date DESC) as r
FROM bookings_table
) a
WHERE a.r = 1Finding cumulative sums —
SELECT Id, StudentName, StudentGender, StudentAge,
SUM (StudentAge) OVER (ORDER BY Id) AS RunningAgeTotal,
AVG (StudentAge) OVER (ORDER BY Id) AS RunningAgeAverage
FROM StudentsRemoving duplicate rows from a table-
select * from (
select row_number() over (partition by cust_email) as r,
cust_name,
cust_email
from cust_data ) a
where a.r = 1and many more problems which I might have not even encountered yet.
Working with Time and Strings
The most common filters I have worked with usually are based on time and strings. Here are some important functions to know for manipulating time
Important date functions
current_date() -- current date
date_sub(current_date(),8) -- gives the date 8 days before today
weekofyear(date_sub(current_date(),8)) --weeknumber of the day 8 days before today
to_date(from_unixtime(cast(metadata_timestamp/1000 as bigint)+19800)) -- timestamp to dateFor string, you should be familiar with all the conditions used in LIKE functions to identify patterns. You can refer to a comprehensive list, but to summarize % is used to denote any number of characters while _ is used to denote a single character. [] can be used in SQL Server to check for multiple characters. Eg. Find names in a Column name where 2nd character has a vowel and last character is ‘t’ —
SELECT name from Table WHERE lower(name) **LIKE '_[aeiou]%t'**
One extra tip, if you export results as .csv always remember to remove commas in all the string column to ensure proper formatting of the file. Use regexp_replace(column_name, ’,’ , ’’) as column_name to remove commas in the column.
Get comfortable with Joins and use proper formatting
Unfortunately you would almost never work with just one table, and most queries will have many sub-queries and joins. So you must always breakdown your given problem into simpler queries and then approach the problem. Basic knowledge of joins is very important in this case. (Also a very common interview question).
The most common join I use is the left join, which is we need to keep all the data from the first table whether or not we get a match in the second table. Let’s see this in the example in the next section.
Also when working with multiple tables, code formatting with proper indentations is the most important. Always keep this in mind while writing any code — if I give this to a 3rd person how easy would it be to comprehend.
Use Cases for filtered counts and sums output
You can always use case when to filter your output, like you use count if in Excel.
(Also another common interview question is the difference between count(*)it returns the number of rows null and non-null vs count(1)Will count all the rows since the expression “1” evaluates to non-null for every row vs count(column_name) Counts rows with non null value for given column)
Let’s see all this in action in the following query where we will try to find out the top Uber drivers in Amsterdam who had the highest cancellations and see their login hours and completed rides. We’ll join the login hours table which has the details of all the logged in drivers with the bookings table which has all the bookings with their status as ‘completed successfully’ or ‘completed early’ or ‘cancelled by customer’ or ‘cancelled by driver’.
select b.license_number, rank() over (order by a.total_canc desc), b.login_hrs, a.total_compl, a.total_canc
(
select lower(city) as city, upper(license_number) as license_number, to_date(`date`) as dt, sum(login_mins) as login_hrs, category
from login_hr_table
where year in (2020)
and to_date(`date`) between date_sub(current_date(),7) and current_date()
and lower(city) in ('amsterdam')
and category in ('cabs')
group by license_number , to_date(`date`), lower(service_city),categor
) as b
left join
(
select to_date(pickup_time) as dt, upper(car_number) as car_number,
count(distinct case when status like '%completed%') then booking_id end) as total_compl,
count(distinct case when status like '%cancelled%') then booking_id end) as total_canc
from booking_details
where year in (2020)
and to_date(pickup_time) between date_sub(current_date(),7) and current_date()
and lower(city) in ('amsterdam')
and category in ('cabs')
group by to_date(pickup_time), car_number
) as a
on a.car_number = b.license_number
and a.dt = b.dtI hope this guide helps you in becoming more confident in writing your SQL queries and tackle next problems you face either as an Analyst or even as an interviewee.
Thanks for reading.